

PandasはPythonでデータ分析を行う際に非常に便利なライブラリです。
特にデータの処理や変換を行うためのツールとして、多くのデータサイエンティストやエンジニアに愛用されています。
その中でも強力な関数の一つが apply関数 です。
今回は、Pandasのapply関数について詳しく解説し、実践的な例を交えながら、どのように使うべきかを紹介していきます。
Pandasのapply関数とは?
apply関数は、DataFrameやSeriesの各要素に対して、指定した関数を適用するためのメソッドです。
これにより、カスタマイズした処理を簡単に行うことができます。
例えば、データの正規化、カスタム集計、新しい列の追加などが簡単に行えます。
SeriesやDataFrameの要素に一斉に何か処理をするのに適しているようだね!
applyの基本的な使い方
Seriesに対するapplyの基本的な使い方
まず、PandasのSeriesオブジェクトに対してapply関数を適用する方法から見ていきましょう。
import pandas as pd
# サンプルデータ
data = [10, 20, 30, 40, 50]
# リストからSeriesを作成
series = pd.Series(data)
# Seriesの要素全体を2倍に
result = series.apply(lambda x: x * 2)
# 出力
print(result)上の例は、Seriesの各要素を2倍にする例です!
DataFrameに対するapplyの基本的な使い方
次にDateFrameに対して、apply関数を適用する方法を見ていきます!
import pandas as pd
# サンプルデータ
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Gender': ['Female', 'Male', 'Male', 'Male', 'Female'],
'Age': [17, 21, 16, 35, 13]
}
# DataFrameの作成
df = pd.DataFrame(data)
# 年齢に基づいてカテゴリを追加する
df['Category'] = df['Age'].apply(lambda x: 'Adult' if x >= 18 else 'Minor')
# 出力
print(df)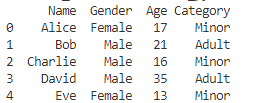
上の例では、DataFrameのAge要素が18以上であれば、「Adult」、それ以外を「Minor」と判定する「Category」をDataFrameに追加しています!
DataFrameに対するapplyの応用例
DataFrame全体に対して関数を適用する場合、apply関数は行方向(axis=1)または列方向(axis=0)に適用できます。
列方向に適用(axis=0)
import pandas as pd
# サンプルデータ
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Gender': ['Female', 'Male', 'Male', 'Male', 'Female'],
'Age': [17, 21, 16, 35, 13]
}
# DataFrameの作成
df = pd.DataFrame(data)
# 各列に対して合計値を計算する
result = df[['Age']].apply(lambda x: x * 2, axis=0)
# 出力
print(result)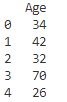
これが「DataFrameに対するapplyの基本的な使い方」で紹介した方法だね!
axis=0はデフォルトなので書かなくても問題ないです!
行方向に適用(axis=1)
import pandas as pd
# サンプルデータ
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Gender': ['Female', 'Male', 'Male', 'Male', 'Female'],
'Age': [17, 21, 16, 35, 13]
}
# DataFrameの作成
df = pd.DataFrame(data)
# 行ごとにName, Gender, Ageの情報を結合して新しい列を作成
df['Summary'] = df.apply(lambda row: f"{row['Name']} は {row['Age']} 歳({row['Gender']})", axis=1)
# 出力
print(df)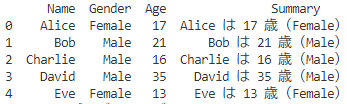
上記のように、行のデータを使って、文字列を作ることもできるし、
すべて数値だったら平均や合計の計算もできるね!
カスタム関数を定義してapplyに渡す
import pandas as pd
# サンプルデータ
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Gender': ['Female', 'Male', 'Male', 'Male', 'Female'],
'Age': [17, 21, 16, 35, 13]
}
# DataFrameの作成
df = pd.DataFrame(data)
# カスタム関数の定義
def categorize_age(age):
if age < 18:
return 'Minor'
elif 18 <= age < 65:
return 'Adult'
else:
return 'Senior'
# apply関数にカスタム関数を渡す
df['Age Category'] = df['Age'].apply(categorize_age)
# 出力
print(df)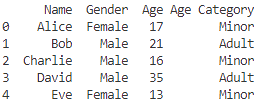
こちらは、Ageから「Senior,Adult,Minor」を判定して、Age Categoryという列を追加するサンプルです!
要するに「Pythonで書ける処理であれば、この書き方をすればなんでもできる」ということです!
まとめ
Pandasのapply関数は、データを柔軟に処理するための非常に強力なツールです。
特に、カスタム関数を適用したり、行や列に対して特定の操作を行いたい場合に重宝します。
ただし、大量のデータに対してはパフォーマンスの低下に注意が必要です。
NumPyなどのライブラリと組み合わせて使うことで、効率的なデータ処理が可能になります。
この記事が、apply関数をより効果的に使うための一助となれば幸いです。ぜひ、実際のデータ分析で試してみてください!


コメント