

データ分析の現場では、異なるデータセットを結合することが多くあります。
例えば、売上データと顧客情報データを結合して売上の詳細を確認したり、在庫情報と商品情報を統合して商品一覧を作成したりと、データセットの結合は業務の幅広い場面で役立ちます。
このような結合操作を簡単に行えるのが、Pythonのデータ分析ライブラリ「Pandas」のmergeメソッドです。
この記事では、Pandasのmergeを使って複数のデータを結合する方法と、使い方の具体例を詳しくご紹介します。
mergeメソッドとは?
mergeメソッドは、Pandasで異なるデータフレームを結合するための基本的な方法です。
主に「キー」となる列を指定し、それを基準にデータを組み合わせます。
これにより、分析対象のデータをより詳細に確認したり、新しい視点で情報を取得したりすることが可能です。
SQLの「JOIN」操作ととても似ているよ!
mergeの基本的な使い方
mergeの基本的な構文
pd.merge(df1, df2, on='キー列', how='結合方法')ここで重要なパラメータは以下の4つです!
df1:結合元のデータフレーム
df2:結合先のデータフレーム
on:結合に使うキー列
how:結合の方法(詳しくは次で説明)
様々な結合方法(inner, outer, left, right)
inner
inner(内部結合):両方のデータフレームに共通するキーのデータのみを結合します。
import pandas as pd
# データフレーム df1(売上データ)
df1 = pd.DataFrame({
'顧客ID': [1, 2, 3, 4],
'売上額': [1000, 1500, 2000, 2500]
})
# データフレーム df2(顧客情報)
df2 = pd.DataFrame({
'顧客ID': [1, 2, 3, 5],
'顧客名': ['田中', '佐藤', '鈴木', '高橋']
})
# 結合実施
merged_df = pd.merge(df1, df2, on='顧客ID', how='inner')
# 出力
print(merged_df)
内部結合なので、結合元と結合先で一致しないもの(ここでいう顧客IDが4,5)は、
結合結果からは削除されています!
また、howのデフォルト値は「inner」なので、指定しなくても良いです!
outer
outer(外部結合):両方のデータフレームの全てのデータを含み、存在しない部分はNaNで埋めます。
import pandas as pd
# データフレーム df1(売上データ)
df1 = pd.DataFrame({
'顧客ID': [1, 2, 3, 4],
'売上額': [1000, 1500, 2000, 2500]
})
# データフレーム df2(顧客情報)
df2 = pd.DataFrame({
'顧客ID': [1, 2, 3, 5],
'顧客名': ['田中', '佐藤', '鈴木', '高橋']
})
# 結合実施
merged_df = pd.merge(df1, df2, on='顧客ID', how='outer')
# 出力
print(merged_df)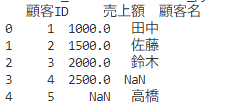
外部結合なので、結合元と結合先で一致しないもの(ここでいう顧客IDが4,5)は、
NaNで適宜埋めることで結合しています!
left
left(左外部結合):左側のデータフレーム(df1)の全てのデータを保持し、右側のデータが存在しない場合はNaNで埋めます。
import pandas as pd
# データフレーム df1(売上データ)
df1 = pd.DataFrame({
'顧客ID': [1, 2, 3, 4],
'売上額': [1000, 1500, 2000, 2500]
})
# データフレーム df2(顧客情報)
df2 = pd.DataFrame({
'顧客ID': [1, 2, 3, 5],
'顧客名': ['田中', '佐藤', '鈴木', '高橋']
})
# 結合実施
merged_df = pd.merge(df1, df2, on='顧客ID', how='left')
# 出力
print(merged_df)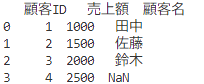
結合元と結合先で一致しないもの(ここでいう顧客IDが4,5)は、
左側のみ残し、NaNで適宜埋めることで結合しています!
right
right(右外部結合):右側のデータフレーム(df2)の全てのデータを保持し、左側のデータが存在しない場合はNaNで埋めます。
import pandas as pd
# データフレーム df1(売上データ)
df1 = pd.DataFrame({
'顧客ID': [1, 2, 3, 4],
'売上額': [1000, 1500, 2000, 2500]
})
# データフレーム df2(顧客情報)
df2 = pd.DataFrame({
'顧客ID': [1, 2, 3, 5],
'顧客名': ['田中', '佐藤', '鈴木', '高橋']
})
# 結合実施
merged_df = pd.merge(df1, df2, on='顧客ID', how='right')
# 出力
print(merged_df)
左外部結合に対し、右外部結合なので、
右側のみ残し、NaNで適宜埋めることで結合しています!
mergeのオプションパラメータ
mergeには、他にも便利なパラメータがいくつかあります。
left_onとright_on
異なる列名を持つデータフレーム同士を結合する際に指定します。
import pandas as pd
# 異なる列名で結合する例
df1 = pd.DataFrame({
'ID1': [1, 2, 3],
'値1': ['A', 'B', 'C']
})
df2 = pd.DataFrame({
'ID2': [1, 2, 4],
'値2': ['X', 'Y', 'Z']
})
# 異なる列名で結合
merged_df = pd.merge(df1, df2, left_on='ID1', right_on='ID2', how='inner')
# 出力
print(merged_df)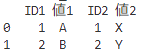
left_on,right_onともに設定してあげることで、
それらの値が等しいものを結合してくれます!
suffixes
同じ名前の列が存在する場合、それぞれにサフィックスを追加します。
例えば、次のように同じ列名の「日付」を持つ2つのデータフレームがあるとします。
import pandas as pd
# データフレーム df1(売上データ)
df1 = pd.DataFrame({
'顧客ID': [1, 2, 3],
'日付': ['2023-01-01', '2023-01-02', '2023-01-03'],
'売上額': [1000, 1500, 2000]
})
# データフレーム df2(返品データ)
df2 = pd.DataFrame({
'顧客ID': [1, 2, 4],
'日付': ['2023-01-05', '2023-01-06', '2023-01-07'],
'返品額': [100, 200, 300]
})
# 顧客IDを基準に結合し、サフィックスを設定
merged_df = pd.merge(df1, df2, on='顧客ID', how='outer', suffixes=('_売上', '_返品'))
print(merged_df)
suffixesパラメータは、pd.merge()で同じ名前の列が複数のデータフレームに存在する場合に、それらの列名にサフィックスを追加して区別するために使われます。
suffixesには、タプル形式でサフィックスを指定します。
mergeとjoinやconcatの違い
Pandasには、mergeの他にもデータ結合の方法としてjoinやconcatも用意されています。
join
インデックスを基準にしてデータフレームを結合します。通常、データのインデックスが整っている場合に使います。
joinについては、以下の記事に詳しくまとめてあります!
よかったらご覧ください!

concat
縦方向または横方向にデータフレームを連結する方法で、データをそのままつなげる場合に便利です。
concatについては、以下の記事に詳しくまとめてあります!
よかったらご覧ください!

mergeは指定した列を基準にして結合するのに対し、joinやconcatは主にインデックスを基準に結合を行う点で異なります。
まとめ
Pandasのmergeメソッドは、データの結合や統合を行う際に非常に便利です。特にデータ分析や集計業務において、複数のデータソースから得た情報を一つにまとめ、分析を進めるための必須テクニックといえます。mergeメソッドを使いこなすことで、異なるデータを有効に結合し、データ分析をより効果的に行えるようになるでしょう。


コメント