

データ分析の現場で使われるPythonのライブラリPandas。
その中でも、データを特定の条件に基づいて集計・要約する際に欠かせないのがgroupbyです。
この記事では、groupbyの基本から応用までを、初心者にもわかりやすく解説し、実際のコード例を通してその効果的な使い方を学びます。
データ分析の幅を広げたい方や、groupbyの理解を深めたい方にとって役立つ内容を目指しています。
Pandasのgroupbyとは?
Pandasのgroupbyは、データフレーム(DataFrame)を特定の列の値でグループ化し、集計や操作を簡単に行えるようにするための機能です。
例えば、売上データを月ごとに集計したり、顧客ごとに平均購入額を計算するようなケースで非常に有効です。
groupbyの主な流れ
- データをグループ化する。
- グループごとに特定の集計や操作を適用する。
このシンプルな手順を理解することで、大量のデータを効率的に処理し、必要な情報を簡単に引き出せます!
groupbyの基本的な使い方
groupbyでデータをグループ化
# グループ化
DateFrame.groupby('カテゴリ名')集計関数を適用する
# 集計関数を適用
grouped['集計対象のカラム'].集計関数()どんな集計関数があるかは、この後、実際にコードを動かしながら見ていくよ!
groupbyでの様々な集計方法
合計(sum)
import pandas as pd
# サンプルデータの作成
data = {
'Category': ['A', 'A', 'B', 'B', 'C', 'C'],
'Sales': [100, 200, 300, 400, 500, 600]
}
# DateFrame作成
df = pd.DataFrame(data)
# グループ化
grouped = df.groupby('Category')
# 集計する
# カテゴリごとの売上合計
category_sales_sum = grouped['Sales'].sum()
# 出力
print(sum)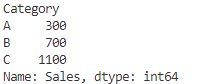
.sum()を使うことで、グループごとの合計が簡単に計算できます!
平均(mean)
import pandas as pd
# サンプルデータの作成
data = {
'Category': ['A', 'A', 'B', 'B', 'C', 'C'],
'Sales': [100, 200, 300, 400, 500, 600]
}
# DateFrame作成
df = pd.DataFrame(data)
# グループ化
grouped = df.groupby('Category')
# 集計する
# カテゴリごとの売上平均
mean= grouped['Sales'].mean()
# 出力
print(mean)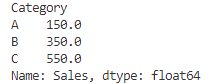
グループごとのデータ数(count)
import pandas as pd
# サンプルデータの作成
data = {
'Category': ['A', 'A', 'B', 'B', 'C', 'C'],
'Sales': [100, 200, 300, 400, 500, 600]
}
# DateFrame作成
df = pd.DataFrame(data)
# グループ化
grouped = df.groupby('Category')
# 集計する
# カテゴリごとのデータ数
count = grouped['Sales'].count()
# 出力
print(count)
グループごとの最小値(min)
import pandas as pd
# サンプルデータの作成
data = {
'Category': ['A', 'A', 'B', 'B', 'C', 'C'],
'Sales': [100, 200, 300, 400, 500, 600]
}
# DateFrame作成
df = pd.DataFrame(data)
# グループ化
grouped = df.groupby('Category')
# 集計する
# カテゴリごとの最小値
min = grouped['Sales'].min()
# 出力
print(min)
グループごとの最大値(max)
import pandas as pd
# サンプルデータの作成
data = {
'Category': ['A', 'A', 'B', 'B', 'C', 'C'],
'Sales': [100, 200, 300, 400, 500, 600]
}
# DateFrame作成
df = pd.DataFrame(data)
# グループ化
grouped = df.groupby('Category')
# 集計する
# カテゴリごとの最大値
max = grouped['Sales'].max()
# 出力
print(max)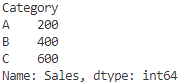
複数列でのグループ化
実際、業務で使う際はもう少し複雑なデータもありますよね!
groupbyでは、複数の列でデータをグループ化することも可能です。
たとえば、カテゴリと日付の組み合わせごとに売上を集計したい場合を考えます。
実装例
import pandas as pd
# サンプルデータの作成
data = {
'Category': ['A', 'A', 'B', 'B', 'C', 'C'],
'Date': ['2021-01-01', '2021-01-02', '2021-01-01', '2021-01-02', '2021-01-01', '2021-01-02'],
'Sales': [100, 200, 300, 400, 500, 600]
}
# DateFrame作成
df = pd.DataFrame(data)
# グループ化
grouped = df.groupby('Category')
# 集計する
category_date_sales = df.groupby(['Category', 'Date'])['Sales'].sum()
# 出力
print(category_date_sales)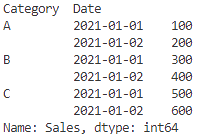
このように、複数の列を使ってグループ化することで、さらに細かい分析が可能です!
グループ化したデータへの複数の集計関数の適用(agg)
groupbyでは、複数の集計関数を一度に適用することも可能です。
これには.agg()を使います。たとえば、カテゴリごとに売上の合計と平均を同時に求める場合は、次のように書きます。
実装例
import pandas as pd
# サンプルデータの作成
data = {
'Category': ['A', 'A', 'B', 'B', 'C', 'C'],
'Sales': [100, 200, 300, 400, 500, 600]
}
# DateFrame作成
df = pd.DataFrame(data)
# グループ化
grouped = df.groupby('Category')
# 集計する
category_agg = df.groupby('Category')['Sales'].agg(['sum', 'mean'])
# 出力
print(category_agg)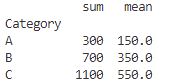
これで一気にデータを集めることも可能になったね!
グループごとに異なる集計関数を適用
各データに対し、別々の集計関数を適用する方法もあります!
import pandas as pd
# サンプルデータの作成
data = {
'Category': ['A', 'A', 'B', 'B', 'C', 'C'],
'Sales': [100, 200, 300, 400, 500, 600],
'Quantity': [1, 2, 3, 4, 5, 6]
}
# DateFrame作成
df = pd.DataFrame(data)
# グループ化
grouped = df.groupby('Category')
# 集計する
category_diff_agg = df.groupby('Category').agg({'Sales': 'sum', 'Quantity': 'mean'})
# 出力
print(category_diff_agg)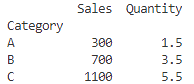
このように、必要に応じて柔軟に集計方法を指定できるため、複雑なデータ処理も簡単に行えます!
まとめ
Pandasのgroupbyは、データの集計や操作を効率的に行うための強力なツールです。
この記事では、groupbyの基本から応用までを解説し、実際のコード例を通して使い方を紹介しました。
複数の列でのグループ化、異なる集計関数の同時適用など、さまざまな機能が揃っているため、データ分析の幅が広がることは間違いありません。
データを深く理解し、より高度な分析を行いたい方は、ぜひgroupbyの使い方をマスターしましょう。


コメント