

データ分析や機械学習において、欠損値(NaNやNone) は避けて通れない課題です。
データに欠損が含まれていると、分析結果に悪影響を及ぼす可能性があります。
Pythonのデータ分析ライブラリ Pandas では、欠損値を処理するための便利なメソッドとして dropna() が提供されています。
今回は、初心者の方にもわかりやすく、dropnaメソッドの使い方とその応用について解説していきます。
この記事を読み終える頃には、データの欠損値に悩まされることなく、スムーズにデータクレンジングを行えるようになるでしょう。
欠損値とは?
まずは、欠損値について簡単に説明します。欠損値(NaN, None)は、データセットの一部が 空白 になっている状態を指します。
欠損値が含まれる原因はさまざまで、データ収集時のエラーや入力ミス、あるいは意図的にデータが省略されている場合などがあります。
例えば、以下のようなデータがあったとしましょう。
| ID | 名前 | 年齢 | 所属 |
|---|---|---|---|
| 1 | 田中 | 29 | 営業 |
| 2 | 鈴木 | NaN | 開発 |
| 3 | 佐藤 | 45 | NaN |
| 4 | NaN | 32 | マーケティング |
このデータでは、年齢や所属、名前の欄に欠損値が含まれています。
dropnaメソッドの基本
Pandasのdropna()メソッドは、欠損値を持つ行や列を 削除 するために使用します。まずは、基本的な使い方を見てみましょう。
行の削除 (axis=0)
import pandas as pd
# サンプルデータを作成
data = {
'ID': [1, 2, 3, 4],
'名前': ['田中', '鈴木', '佐藤', None],
'年齢': [29, None, 45, 32],
'所属': ['営業', '開発', None, 'マーケティング']
}
# データフレームの削除
df = pd.DataFrame(data)
# 行単位での削除(デフォルト)
df_cleaned = df.dropna(axis=0)
# 出力
print(df_cleaned)

デフォルトでは、axis=0が設定されているため、行単位で削除が行われます。
デフォルトなので、axisを指定しなくても行単位の削除ができるよ!
列の削除 (axis=1)
import pandas as pd
# サンプルデータを作成
data = {
'ID': [1, 2, 3, 4],
'名前': ['田中', '鈴木', '佐藤', None],
'年齢': [29, None, 45, 32],
'所属': ['営業', '開発', None, 'マーケティング']
}
# データフレームの削除
df = pd.DataFrame(data)
# 列単位での削除
df_cleaned = df.dropna(axis=1)
# 出力
print(df_cleaned)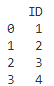
この場合、年齢、名前、所属の列に欠損値が含まれているため、それらの列はすべて削除されています!
欠損値が一部でも残る行・列を削除しない場合
全ての値が欠損値・一部の値が欠損値
データによっては、1つの列に欠損値が含まれているだけで削除してしまうのはもったいない場合があります。
そのような時には、howパラメータを活用しましょう。
how=’all’の使用例
import pandas as pd
# サンプルデータを作成
data = {
'ID': [1, 2, None, 4],
'名前': ['田中', '鈴木', None, None],
'年齢': [29, None, None, 32],
'所属': ['営業', '開発', None, 'マーケティング']
}
# データフレームの削除
df = pd.DataFrame(data)
# すべての値がNaNの場合にのみ削除
df_cleaned = df.dropna(how='all')
# 出力
print(df_cleaned)
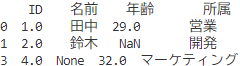
how=’all’は、すべての値が欠損値 の場合にのみ削除を行います。
how=’any’の使用例
import pandas as pd
# サンプルデータを作成
data = {
'ID': [1, 2, 3, 4],
'名前': ['田中', '鈴木', '佐藤', None],
'年齢': [29, None, 45, 32],
'所属': ['営業', '開発', None, 'マーケティング']
}
# データフレームの削除
df = pd.DataFrame(data)
# どれか一つでもNaNがある場合に削除
df_cleaned = df.dropna(how='any')
# 出力
print(df_cleaned)

デフォルトでは、how=’any’が設定されており、いずれかの値が欠損 している場合に行または列が削除されます。
非欠損値の数を指定して削除 (thresh)
特定の数以上の非欠損値がある行のみ残す(それ以外を削除)を行いたい場合には、threshパラメータが便利です。
import pandas as pd
# サンプルデータを作成
data = {
'ID': [1, 2, 3, 4],
'名前': ['田中', None, '佐藤', None],
'年齢': [29, None, None, 32],
'所属': ['営業', None, None, 'マーケティング']
}
# データフレームの削除
df = pd.DataFrame(data)
# 非欠損値が2つ以上ある行を残す
df_cleaned = df.dropna(thresh=2)
# 出力
print(df_cleaned)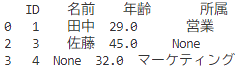
thresh=2では、非欠損値が 2つ以上 ある行は削除されずに残ります!
特定の列のみをチェックして削除 (subset)
特定の列に欠損値がある行のみ削除したい場合には、subsetパラメータが役立ちます。
import pandas as pd
# サンプルデータを作成
data = {
'ID': [1, 2, 3, 4],
'名前': ['田中', '鈴木', '佐藤', None],
'年齢': [29, None, 45, 32],
'所属': ['営業', '開発', None, 'マーケティング']
}
# データフレームの削除
df = pd.DataFrame(data)
# '年齢'列に欠損値がある行を削除
df_cleaned = df.dropna(subset=['年齢'])
# 出力
print(df_cleaned)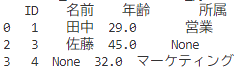
まとめ
Pandasのdropna()は、データクレンジングの第一歩として非常に重要なメソッドです。
データの欠損値を効率よく処理することで、分析結果の精度を向上させることができます。
今回紹介したオプションを活用することで、より柔軟な欠損値処理が可能になります。
データがきれいになると、分析が進みやすくなり、さらに深いインサイトを得られるようになります。
ぜひ、dropna()の使い方をマスターして、データ分析をよりスムーズに進めてみてください!


コメント