

Pythonを使ったデータ分析や機械学習のプロジェクトでは、データを操作・加工した後にファイルとして保存する場面が多くあります。その際によく使用される形式が「CSVファイル」です。
CSV(Comma-Separated Values)は、データをカンマで区切ったシンプルなフォーマットで、ExcelやGoogleスプレッドシートなどのツールでも簡単に読み込むことができます。
この記事では、Pythonのデータ操作ライブラリ「Pandas」を使って、データフレーム(DataFrame)をCSVファイルとして出力する方法を詳しく解説します。
初心者でも分かりやすく、ステップバイステップで説明するので安心してください!
Pandasとは?
Pandasは、Pythonでデータ操作や分析を行うためのライブラリで、データフレーム(DataFrame)と呼ばれるデータ構造を使用します。
このデータフレームは、行と列からなる表形式のデータを扱うためのもので、Excelシートのように直感的にデータを操作することができます。
Pandasは、データの読み込み・整理・分析・出力を効率的に行えるため、データサイエンティストやエンジニアにとって必須のツールです!
Pandasについてやインストール方法など、もっと詳しく知りたい方は、次の記事を読んで下さい!

PandasでデータフレームをCSVファイルに出力する基本
PandasでCSVファイルにデータを出力するためには、to_csv() メソッドを使用します。to_csv() メソッドは、データフレームをCSVファイルとして保存するためのシンプルで強力な方法です。
基本的なCSV出力
import pandas as pd
# サンプルデータの作成
data = {
'名前': ['田中', '鈴木', '佐藤'],
'年齢': [25, 30, 35],
'職業': ['エンジニア', 'デザイナー', 'データサイエンティスト']
}
# データフレームの作成
df = pd.DataFrame(data)
# CSVファイルに出力
df.to_csv('sample.csv', index=False)
# 結果出力
print("CSVファイル 'sample.csv' が作成されました。")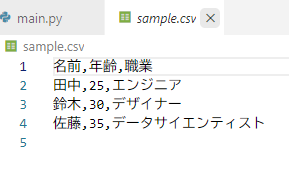
to_csv() メソッドの引数としてファイル名(ここでは ‘sample.csv’)を指定します!
index=False とすることで、データフレームのインデックス(行番号)がCSVファイルに書き出されないようにします。インデックスが不要な場合は、このオプションを付けると便利です。
to_csv() メソッドの便利なオプション
to_csv() メソッドには、多くの便利なオプションが用意されています。これらを活用することで、データの出力方法を細かく制御できます。
カンマ以外の区切り文字を使用する
CSVの「C」は「Comma(カンマ)」を意味しますが、データにカンマが含まれる場合などには、別の区切り文字を使用することができます。
import pandas as pd
# サンプルデータの作成
data = {
'名前': ['田中', '鈴木', '佐藤'],
'年齢': [25, 30, 35],
'職業': ['エンジニア', 'デザイナー', 'データサイエンティスト']
}
# データフレームの作成
df = pd.DataFrame(data)
# タブ区切りのCSVファイルとして保存
df.to_csv('sample_tab.csv', sep='\t', index=False)
# 結果出力
print("CSVファイル 'sample_tab.csv' が作成されました。")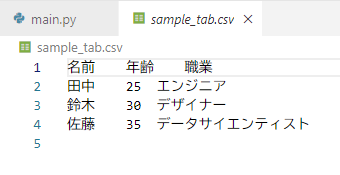
特定の列だけを出力する
import pandas as pd
# サンプルデータの作成
data = {
'名前': ['田中', '鈴木', '佐藤'],
'年齢': [25, 30, 35],
'職業': ['エンジニア', 'デザイナー', 'データサイエンティスト']
}
# データフレームの作成
df = pd.DataFrame(data)
# '名前'と'年齢'の列だけを出力
df.to_csv('sample_columns.csv', columns=['名前', '年齢'], index=False)
# 結果出力
print("CSVファイル 'sample_columns.csv' が作成されました。")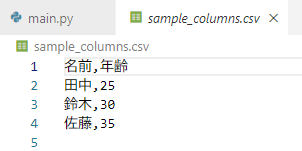
データフレームの中から特定の列だけをCSVに書き出したい場合は、columns オプションを使用します!
エンコーディングを指定する
import pandas as pd
# サンプルデータの作成
data = {
'名前': ['田中', '鈴木', '佐藤'],
'年齢': [25, 30, 35],
'職業': ['エンジニア', 'デザイナー', 'データサイエンティスト']
}
# データフレームの作成
df = pd.DataFrame(data)
# Shift JISでエンコード
df.to_csv('sample_sjis.csv', index=False, encoding='shift_jis')
# 結果出力
print("CSVファイル 'sample_sjis.csv' が作成されました。")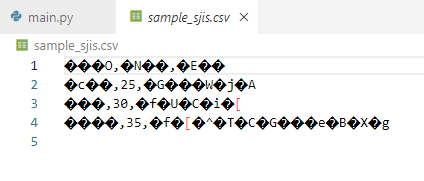
CSVファイルのエンコーディングは、特に日本語などマルチバイト文字を含む場合に重要です!デフォルトではUTF-8ですが、Excelで開く場合には shift_jis を指定すると便利です!
欠損値の扱い
データフレームには欠損値(NaN)が含まれることがよくあります。
to_csv() では、欠損値を特定の文字列に置き換えて出力することが可能です。
import pandas as pd
# サンプルデータの作成
data = {
'名前': [None, '鈴木', '佐藤'],
'年齢': [25, None, 35],
'職業': ['エンジニア', 'デザイナー', None]
}
# データフレームの作成
df = pd.DataFrame(data)
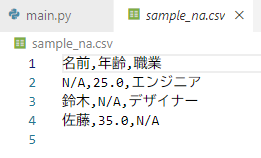
# 欠損値を 'N/A' として出力
df.to_csv('sample_na.csv', index=False, na_rep='N/A')
# 結果出力
print("CSVファイル 'sample_na.csv' が作成されました。")
まとめ
Pandasの to_csv() メソッドを使うと、データフレームのデータを簡単にCSVファイルに書き出すことができます。
基本的な使い方から便利なオプションまで紹介しましたが、実際の業務ではこれらを組み合わせて効率的にデータを保存することが求められます。
ポイント
- index=False でインデックスの出力を制御
- sep オプションで区切り文字を変更
- columns オプションで特定の列を指定
- encoding でエンコーディングを調整
これで、Pandasを使ったCSV出力がしっかりと理解できたのではないでしょうか。ぜひ、次のプロジェクトで活用してみてください!
CSV出力はわかったけど、逆に
CSVを読み込むときはどうしたらいいの?
という方は次の記事を読んでみてください!よいPandasライフを!



コメント