

Pandasは、Pythonでデータ分析を行う上で非常に便利なライブラリです。
特に、データをソート(並べ替え)する機能はよく使用されます。
この記事では、Pandasのsort_values()やsort_index()を使ったデータの並べ替え方法について、初心者でもわかりやすく解説していきます。
指定した列を基にデータの並べ替え(sort_values)
sort_values()の基本的な使い方
Pandasのsort_values()関数は、指定した列を基にデータを並べ替えることができます。
import pandas as pd
# サンプルデータを作成
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [24, 19, 30, 22, 25],
'Score': [85, 92, 78, 90, 88]
}
# データフレームを作成
df = pd.DataFrame(data)
# 'Age'列でソート
sorted_df = df.sort_values(by='Age')
# 出力
print(sorted_df)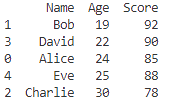
sort_values(by=’Age’)で、Age列を基に昇順でソートされています。
by引数には、ソートしたい列名を指定します。
昇順・降順の切り替え
デフォルトでは昇順にソートされますが、降順にソートしたい場合は、ascending=Falseを使用します!
import pandas as pd
# サンプルデータを作成
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [24, 19, 30, 22, 25],
'Score': [85, 92, 78, 90, 88]
}
# データフレームを作成
df = pd.DataFrame(data)
# 'Score'列で降順にソート
sorted_df = df.sort_values(by='Score', ascending=False)
# 出力
print(sorted_df)
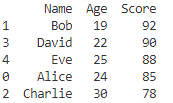
複数のカラムでソートする方法
複数の列を基にソートすることもできます。
例えば、Ageで昇順にソートし、その次にScoreで降順にソートしたいとします!
import pandas as pd
# サンプルデータを作成
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [24, 19, 30, 22, 25],
'Score': [85, 92, 78, 90, 88]
}
# データフレームを作成
df = pd.DataFrame(data)
# 'Age'で昇順、'Score'で降順にソート
sorted_df = df.sort_values(by=['Age', 'Score'], ascending=[True, False])
# 出力
print(sorted_df)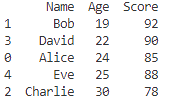
インデックスを並べ替える(sort_index)
データフレームにはインデックスが設定されていることが多く、これを基に並べ替えることも可能です。
sort_index()を使ってインデックスでソートする例を紹介します。
import pandas as pd
# サンプルデータを作成
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [24, 19, 30, 22, 25],
'Score': [85, 92, 78, 90, 88]
}
# データフレームを作成
df = pd.DataFrame(data)
# インデックスを降順にソート
sorted_df = df.sort_index(ascending=False)
# 出力
print(sorted_df)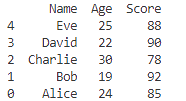
sort_index()はインデックスを基にデータを並べ替えます!
ascending=Falseで降順に並べ替えができます!
並べ替えのパフォーマンスを考慮した
大量のデータを扱う場合、並べ替え操作は時間がかかることがあります。その際に役立つヒントをいくつか紹介します。
inplace=Trueでメモリ使用量を抑える
sort_values()やsort_index()ではinplace=Trueを設定することで、元のデータフレームを直接変更できます。
import pandas as pd
# サンプルデータを作成
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [24, 19, 30, 22, 25],
'Score': [85, 92, 78, 90, 88]
}
# データフレームを作成
df = pd.DataFrame(data)
# メモリ節約のためにinplace=Trueを使用
df.sort_values(by='Age', inplace=True)
# 出力
print(df)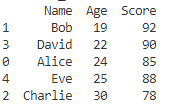
kindオプションでソートアルゴリズムを指定
デフォルトでは、Pandasはquicksortアルゴリズムを使用しますが、データの特性に応じてmergesortやheapsortを指定することでパフォーマンスが向上することがあります。
import pandas as pd
# サンプルデータを作成
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [24, 19, 30, 22, 25],
'Score': [85, 92, 78, 90, 88]
}
# データフレームを作成
df = pd.DataFrame(data)
# 'mergesort'を使用して安定ソート
df.sort_values(by='Age', kind='mergesort', inplace=True)
# 出力
print(df)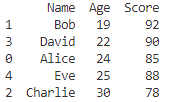
大量のデータを読み込んで、いろいろなソートを試してみよう!
まとめ
Pandasのsort_values()とsort_index()を使えば、データの並べ替えが非常に簡単に行えます。
この記事で紹介した内容をマスターすれば、データの可読性が向上し、より効率的な分析が可能になるでしょう。
特に、複数のカラムでのソートやパフォーマンスを考慮したソートを覚えておくと、大量のデータを扱う際に役立ちます。


コメント