

データ分析の作業で必ず直面するのが、「重複データ」や「一意性」を扱う課題です。
膨大なデータの中から重複している値を探したり、一意な値を抽出したりするのは一見面倒に思えますが、Pythonのデータ分析ライブラリ「Pandas」を使えばその手間を大幅に削減できます。
特に、uniqueという関数を使えば簡単にこの課題を解決できます。
この記事では、Pandasのunique関数について、その基本的な使い方から応用まで詳しく解説します。データ分析初心者の方から上級者まで役立つ内容となっていますので、ぜひ最後までご覧ください!
Pandasとは?
まず、簡単にPandasについておさらいしましょう。
Pandasは、Pythonでデータを操作するためのライブラリで、データの読み込み、加工、集計、解析、可視化などを簡単に行うことができます。
その中でも、DataFrameやSeriesといったデータ構造が特徴的で、大量のデータを効率よく操作できるのが強みです。
より詳しく知りたい方は、次の記事を見てください!

unique関数の基本
Pandasのunique関数は、Seriesオブジェクトに含まれる一意な値を取り出すための関数です。
この関数を使えば、簡単にデータ内の重複を排除し、一意な要素をリストとして取得できます。
DataFrameも1列を切り出せば、Seriesオブジェクトだから使えるよ!
基本構文
Series.unique()ここで重要なのは、uniqueはSeriesオブジェクト専用である点です。DataFrameに対して直接使うことはできませんが、列(Series)を指定することで間接的に利用可能です。
uniqueの基本的な使い方
Seriesでのuniqueの使用例
import pandas as pd
# サンプルデータ
data = pd.Series([1, 2, 2, 3, 4, 4, 4, 5])
# 一意な値を取得
unique_values = data.unique()
# 出力
print(unique_values)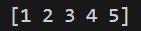
この例では、1, 2, 3, 4, 5という一意な値がリストとして返されました。
重複している値(例: 2や4)は自動的に取り除かれます!
DataFrameでのuniqueの使用例
import pandas as pd
# サンプルデータフレーム
df = pd.DataFrame({
"name": ["Alice", "Bob", "Alice", "David"],
"score": [85, 90, 85, 88]
})
# 'name'列の一意な値を取得
unique_names = df["name"].unique()
# 出力
print(unique_names)
DataFrameから特定の列に含まれる一意な値を取得したい場合も、
uniqueを使って簡単に実現できます。
応用例: データの頻度解析と組み合わせる
一意な値を取得するだけでなく、それぞれの値が何回出現しているのかも知りたい場合があります。
その場合は、value_counts関数と組み合わせると便利です!
import pandas as pd
# サンプルデータ
data = pd.Series([1, 2, 2, 3, 4, 4, 4, 5])
# 出現回数をカウント
value_counts = data.value_counts()
# 出力
print(value_counts)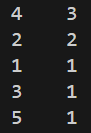
注意点と落とし穴
順序は保持されるが整列されない
unique関数が返す結果は、元データの順序を保ちながら一意な値を出力しますが、昇順や降順にはなりません。
必要に応じてsorted()を併用しましょう。
NaNの扱い
データにNaNが含まれている場合、unique関数はこれを含めて出力します。
ただし、NaNは他のNaNと等しいと見なされるため、重複してカウントされることはありません。
まとめ
Pandasのunique関数は、一意な値を簡単に抽出するための非常に強力なツールです!
基本的な使い方から、応用的な頻度解析やデータクレンジングまで、幅広い場面で役立ちます!
この記事の内容を参考に、日々のデータ分析作業を効率化してみてください。
uniqueを活用することで、データの一意性を素早く把握し、より質の高い分析が可能になります。

コメント