

Pandasを使用するうえで最も基本かつ重要なデータ構造が「DataFrame」です。DataFrameは行と列の二次元構造を持つため、エクセルの表と似た構造を持っていますが、Pythonのコード内で直接操作できるため、データの管理・分析が圧倒的に便利です。
本記事では、基本的な使い方から実践的なテクニックまでを初心者向けに詳しく解説していきます。
DataFrameとは?
DataFrameは、表形式データを効率的に扱うためのPandasの主要なデータ構造で、行と列のラベルが付いているため、データを容易に管理・操作することができます。DataFrameを活用することで、データのフィルタリング、変換、並び替え、集計といった処理を高速に行うことができます。
Pandas DataFrameは以下のような場面で特に有効です:
- 大量のデータを迅速に処理したいとき
- データのクリーニングや整形を効率的に行いたいとき
- グルーピングや集計など、データ分析を行いたいとき
DataFrameの作成方法
DataFrameはさまざまな方法で作成することができます。まず、基本的なデータの作成例を見ていきましょう。
リストを使用して作成
import pandas as pd
# データの定義
data = [[1, 'Alice', 24], [2, 'Bob', 27], [3, 'Charlie', 22]]
# データフレームの作成
df = pd.DataFrame(data, columns=['ID', 'Name', 'Age'])
# 出力
print(df)
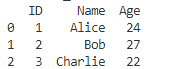
上記のコードでは、dataというリストをもとに、ID、Name、Ageという3列のDataFrameを作成しています。
辞書を使用して作成
import pandas as pd
# データの定義
data = {'ID': [1, 2, 3], 'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [24, 27, 22]}
# データフレームの作成
df = pd.DataFrame(data)
# 出力
print(df)
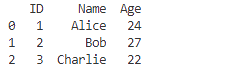
この場合、辞書のキーが列の名前として使用され、それぞれのキーに対応するリストが各列のデータとなります!
CSVファイルから読み込む
実際のデータ解析では、CSVファイルやExcelファイルからDataFrameを作成することが多いです。
import pandas as pd
# データフレームの作成
df = pd.read_csv("sample_data.csv")
# 出力
print(df)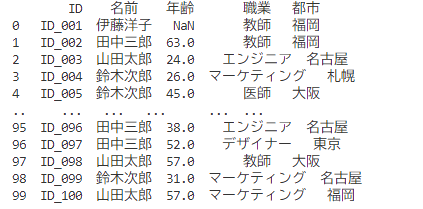
このように、read_csv()関数を使うだけで、簡単にDataFrameを作成できます。
read_csvの使い方については、以下の記事に詳しくまとめています!
よかったらご覧ください!

DataFrameの基本操作
DataFrameには、データの表示や確認、基本操作に関する便利なメソッドが数多く用意されています。
データの表示(先頭)
DataFrameの先頭数行を確認するには、head()メソッドを使用します。引数を指定しない場合、デフォルトで5行分のデータが表示されます。
print(df.head(5))データの表示(末尾)
データの末尾を確認したい場合は、tail()メソッドを使用します。
print(df.tail(5))データの情報確認
列のデータ型や欠損値の数などの基本情報
print(df.info())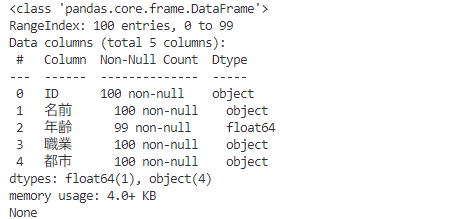
データの数なども教えてくれるので、
ファイルを開かなくても、どうコードを書くかの参考になるね!
数値列の統計情報(平均、標準偏差など)
print(df.describe())
データから数値を探して、いろいろな統計情報を取得してくれます!
データのフィルタリングと抽出
特定の列を抽出する
特定の列のみを抽出したい場合は、列名を指定します。複数の列を抽出したい場合は、リストで列名を指定します。
import pandas as pd
# データフレームの作成
df = pd.read_csv("sample_data.csv")
# '名前' 列のみを抽出
print(df[['ID', '名前']])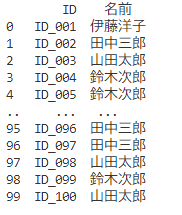
条件に基づくフィルタリング
データを条件に基づいて抽出することも簡単です。例えば、Age列の値が25以上の行を抽出する場合は以下のようにします。
import pandas as pd
# データフレームの作成
df = pd.read_csv("sample_data.csv")
# 年齢>=45のデータのみの抽出
filtered_df = df[df['年齢'] >= 45]
# 出力
print(filtered_df)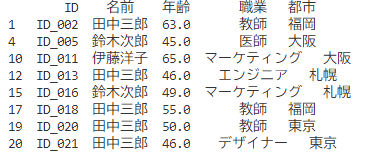
データの変換と整形
データ解析を行う前に、データを整形・変換することがよくあります。以下にいくつかの変換例を紹介します。
列の追加
新しい列を追加するには、単純に新しい列名と値を指定します。たとえば、Age列の値に1を加えたNew_Age列を追加する場合は以下のようにします。
# 5年後の年齢の追加
df['5年後の年齢'] = df['年齢'] + 5
# 出力
print(df)
列の削除
不要な列を削除するには、drop()メソッドを使います。
# 年齢の列の削除
df = df.drop(columns=['年齢'])
# 出力
print(df)
データの並び替え
DataFrameを特定の列で並び替えるには、sort_values()メソッドを使用します。
# 年齢の降順に並び替え
df = df.sort_values(by='年齢', ascending=False)
# 出力
print(df)
データの集計とグルーピング
グルーピングと集計
groupby()メソッドを使うと、特定の列でデータをグループ化し、その後の集計が簡単に行えます。
# 年齢でグルーピングし、件数をカウント
grouped_df = df.groupby('年齢').count()
# 出力
print(grouped_df)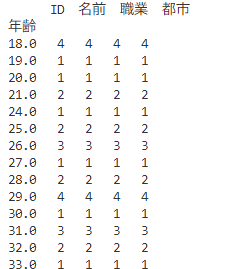
上記の例では、年齢列でデータをグループ化し、それぞれのグループにおける行数を数えています。
ピボットテーブルの作成
Excelのピボットテーブルのように、Pandasでもデータの集計やクロス集計ができます。
# 年齢でグルーピングし、件数をカウント
pivot_table = df.pivot_table(index='名前', values='年齢', aggfunc='mean')
# 出力
print(pivot_table)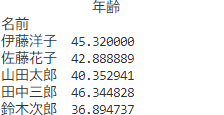
DataFrameデータの可視化
Pandasは、MatplotlibやSeabornといった可視化ライブラリと組み合わせてデータの視覚化も可能です。
import pandas as pd
import matplotlib.pyplot as plt
# データフレームの作成
df = pd.read_csv("sample_data.csv")
# 可視化
df['年齢'].plot(kind='bar')
plt.xlabel('Index')
plt.ylabel('Age')
plt.title('Age Distribution')
plt.show()
上記のコードでは、Age列のデータを棒グラフとして表示しています。
まとめ
PandasのDataFrameは、データを扱う際に非常に便利で強力なツールです。本記事では、DataFrameの基本的な操作方法から応用的な使い方までを紹介しました。DataFrameの操作に慣れると、データ解析やデータサイエンスの作業がより効率的になります。ぜひPandas DataFrameを使いこなして、データの可能性を引き出してみてください!
Pandasを勉強中の方には次の記事がオススメです!



コメント