

データ分析や可視化の際に、特にPythonを使って作業している場合、Pandasは最も頼れるライブラリのひとつです。
その中でも、データを整理して洞察を得るための強力な機能のひとつがピボットテーブル(Pivot Table)です。
Excelユーザーには馴染みがあると思いますが、Pandasのピボットテーブル(Pivot Table)はさらに柔軟で、多機能です。
この記事では、Pandasのピボットテーブル(Pivot Table)について、初心者にもわかりやすく解説し、実際の使用例を交えながら、ピボットテーブル(Pivot Table)の使い方や応用方法を学んでいきます。
Pandasのピボットテーブル(Pivot Table)とは?
ピボットテーブル(Pivot Table)とは、データを再構築して要約するための表の一種です。
複雑なデータセットに対して、列や行でグループ化した集計結果を得ることができます。
例えば、売上データをカテゴリごとや月ごとに集計したい場合に便利です。
PythonのPandasライブラリには、pivotとpivot_tableという2つの関数がありますが、この記事ではより柔軟なpivot_tableに焦点を当てます。
pivot_tableの基本構文
pivot_table関数の基本的な構文は以下のとおりです。
import pandas as pd
pd.pivot_table(data, values, index, columns, aggfunc)- data:ピボットテーブル(Pivot Table)を作成する元データ
- values:集計したい値(列)
- index:行として使用する列
- columns:列として使用する列
- aggfunc:集計関数(デフォルトは平均)
pivot_tableのつくり方はこんな感じ!
実際にpivot_tableを使ってみよう!
ピボットテーブル(Pivot Table)の作成
基本的なピボットテーブル(Pivot Table)の作成
import pandas as pd
# サンプルデータの作成
data = {
"Date": ["2024-01-01", "2024-01-02", "2024-01-01", "2024-01-02", "2024-01-01", "2024-01-02"],
"Product": ["Apple", "Apple", "Banana", "Banana", "Orange", "Orange"],
"Sales": [200, 150, 100, 120, 300, 250],
"Quantity": [10, 8, 5, 6, 15, 12]
}
# データフレームの作成
df = pd.DataFrame(data)
# ピボットテーブル(Pivot Table)の作成
pivot_table = pd.pivot_table(df, values="Sales", index="Product", aggfunc="mean")
# 出力
print(pivot_table)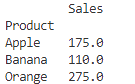
このように、Product(商品)をインデックスにして、Sales(売上)の平均値が計算されました!
複数の集計関数を使用する
pivot_table関数は、複数の集計関数を同時に使用することも可能です。
import pandas as pd
# サンプルデータの作成
data = {
"Date": ["2024-01-01", "2024-01-02", "2024-01-01", "2024-01-02", "2024-01-01", "2024-01-02"],
"Product": ["Apple", "Apple", "Banana", "Banana", "Orange", "Orange"],
"Sales": [200, 150, 100, 120, 300, 250],
"Quantity": [10, 8, 5, 6, 15, 12]
}
# データフレームの作成
df = pd.DataFrame(data)
# ピボットテーブル(Pivot Table)の作成
pivot_table = pd.pivot_table(df, values=["Sales", "Quantity"], index="Product", aggfunc={"Sales": "sum", "Quantity": "sum"})
# 出力
print(pivot_table)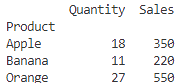
複数のインデックスと列でのグループ化
より複雑なデータセットでは、複数のインデックスや列を指定することもできます。
import pandas as pd
# サンプルデータの作成
data = {
"Date": ["2024-01-01", "2024-01-02", "2024-01-01", "2024-01-02", "2024-01-01", "2024-01-02"],
"Product": ["Apple", "Apple", "Banana", "Banana", "Orange", "Orange"],
"Sales": [200, 150, 100, 120, 300, 250],
"Quantity": [10, 8, 5, 6, 15, 12]
}
# データフレームの作成
df = pd.DataFrame(data)
# ピボットテーブル(Pivot Table)の作成
pivot_table = pd.pivot_table(df, values="Sales", index=["Date", "Product"], aggfunc="sum")
# 出力
print(pivot_table)集計結果が欠損値だった場合の補完
import pandas as pd
import numpy as np
# サンプルデータの作成
data = {
"Date": ["2024-01-01", "2024-01-02", "2024-01-01", "2024-01-02", "2024-01-01", "2024-01-02"],
"Product": ["Apple", "Apple", "Banana", "Banana", "Orange", "Orange"],
"Sales": [np.nan, np.nan, 100, 120, 300, 250],
"Quantity": [10, 8, 5, 6, 15, 12]
}
# データフレームの作成
df = pd.DataFrame(data)
# ピボットテーブル(Pivot Table)の作成
pivot_table = pd.pivot_table(df, values="Sales", index="Product", aggfunc="sum", fill_value=0)
# 出力
print(pivot_table)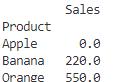
Appleの集計結果がNaNとなってしまいますが、0として出力されているのがわかります!
ちなみにnp.nanは、numpyで欠損値を意図的に作ります!
pivot関数との違い
最後に、pivot_tableと似ているpivot関数について少し触れておきます。
pivotは基本的にデータの再配置に使われ、集計は行いません。そのため、複数の値がある場合にはエラーとなります。
import pandas as pd
import numpy as np
# サンプルデータの作成
data = {
"Date": ["2024-01-01", "2024-01-02", "2024-01-01", "2024-01-02", "2024-01-01", "2024-01-02"],
"Product": ["Apple", "Apple", "Banana", "Banana", "Orange", "Orange"],
"Sales": [100, 200, 100, 120, 300, 250],
"Quantity": [10, 8, 5, 6, 15, 12]
}
# データフレームの作成
df = pd.DataFrame(data)
# ピボット(Pivot)の作成
pivot = df.pivot(index="Date", columns="Product", values="Sales")
# 出力
print(pivot)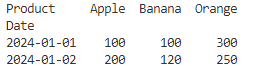
pivot 関数については別の記事にまとめたよ!
ぜひ、ご覧ください!
※現在、執筆中…
まとめ
Pandasのピボットテーブル(Pivot Table)は、データを効率的に整理し、洞察を得るための強力なツールです。
初心者でも理解しやすいシンプルな構造でありながら、複雑な分析にも対応できる柔軟性があります。
この記事で紹介した基本操作をマスターすれば、実務で役立つ高度な分析が可能になります。


コメント