

Pandasは、Pythonのデータ解析に欠かせないライブラリの一つです。
その中でも、DataFrameは表形式のデータを扱うための重要なデータ構造です。
DataFrameを効果的に操作するためには、「インデックス(index)」の理解が不可欠です。
本記事では、PandasのDataFrameインデックス(index)について、その基礎から応用まで解説し、データ分析のスキルをレベルアップするための実践的なテクニックを紹介します。
インデックス(index)とは?
DataFrameのインデックス(index)は、データを参照するためのラベルです。
行や列の識別子として機能し、データへの高速アクセスや操作が可能になります。
インデックス(index)はデフォルトでは0から始まる整数が設定されますが、特定の列をインデックス(index)に設定したり、複数の列をインデックスに設定したりできます。
デフォルトのインデックス(index)の確認
import pandas as pd
# サンプルデータの作成
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']}
# データフレームの作成
df = pd.DataFrame(data)
# 出力
print(df)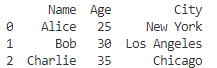
この場合、インデックス(index)はデフォルトの0, 1, 2,…す。しかし、インデックス(index)を変更することで、データの検索やフィルタリングがより便利になります。
インデックス(index)の操作
インデックス(index)の設定
import pandas as pd
# サンプルデータの作成
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']}
# データフレームの作成
df = pd.DataFrame(data)
# 'Name'列をインデックスに設定
df = df.set_index('Name')
# 出力
print(df)
このように設定すると、Name列がインデックス(index)となり、行のラベルとして使用できます。
マルチインデックス
複数の列をインデックス(index)に設定することも可能です。これをマルチインデックスと言います。
import pandas as pd
# サンプルデータの作成
data = {'Country': ['USA', 'USA', 'Canada', 'Canada'],
'State': ['New York', 'California', 'Ontario', 'Quebec'],
'Population': [19, 39, 14, 8]}
# データフレームの作成
df = pd.DataFrame(data)
# 'Name'列をインデックスに設定
df = df.set_index(['Country', 'State'])
# 出力
print(df)
このように設定することで、複雑なデータ構造を持つデータフレームをよりわかりやすく管理できます!
インデックス(index)のリセット
インデックス(index)を設定した後、元の状態に戻したい場合は、reset_index() メソッドを使います。
import pandas as pd
# サンプルデータの作成
data = {'Country': ['USA', 'USA', 'Canada', 'Canada'],
'State': ['New York', 'California', 'Ontario', 'Quebec'],
'Population': [19, 39, 14, 8]}
# データフレームの作成
df = pd.DataFrame(data)
# 'Name'列をインデックスに設定
df = df.set_index(['Country', 'State'])
# インデックスをリセット
df = df.reset_index()
# 出力
print(df)
リセットすると、インデックス(index)は再びデフォルトの整数インデックス(index)に戻ります!
インデックス(index)の取得
import pandas as pd
# サンプルデータの作成
data = {'Country': ['USA', 'USA', 'Canada', 'Canada'],
'State': ['New York', 'California', 'Ontario', 'Quebec'],
'Population': [19, 39, 14, 8]}
# データフレームの作成
df = pd.DataFrame(data)
# 'Name'列をインデックスに設定
df = df.set_index('Country')
# インデックスの確認
print(df.index)
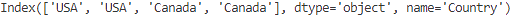
DataFrameのインデックス(index)を確認したい場合、df.indexを使います。これにより、現在のインデックス(index)がどのような状態かを確認できます。
インデックスでのソート (sort_index())
インデックス(index)は通常、設定した順序のままですが、特定の場面ではインデックス(index)でソートすることが役立ちます。sort_index()メソッドを使えば、インデックス(index)順にDataFrame全体を並び替えることができます。
import pandas as pd
# サンプルデータの作成
data = {'Country': ['USA', 'USA', 'Canada', 'Canada'],
'State': ['New York', 'California', 'Ontario', 'Quebec'],
'Population': [19, 39, 14, 8]}
# データフレームの作成
df = pd.DataFrame(data)
# 'Name'列をインデックスに設定
df = df.set_index('Country')
# インデックスを並び替え
sorted_df = df.sort_index()
print(sorted_df)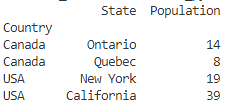
インデックス(index)がアルファベット順や数値順にソートされるため、データの可視化や分析がしやすくなります。また、降順でソートしたい場合は、ascending=Falseオプションを使用します。
インデックスがユニークか確認 (df.index.is_unique)
インデックス(index)がユニークであるかどうかを確認することは、データの品質をチェックする際に重要です。ユニークなインデックス(index)は、データの正確な検索や操作を保証します。df.index.is_uniqueを使うと、インデックス(index)がユニークならTrue、重複があればFalseが返されます。
import pandas as pd
# サンプルデータの作成
data = {'Country': ['USA', 'USA', 'Canada', 'Canada'],
'State': ['New York', 'California', 'Ontario', 'Quebec'],
'Population': [19, 39, 14, 8]}
# データフレームの作成
df = pd.DataFrame(data)
# 'Name'列をインデックスに設定
df = df.set_index('Country')
# インデックスのユニーク性を確認
print(df.index.is_unique)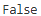
インデックスが重複している場合、データの検索や更新時に予期せぬ結果を招く可能性があります。そのため、インデックスの設定後に必ずユニーク性を確認することが推奨されます。
まとめ
PandasのDataFrameインデックス(index)は、データ操作の基本かつ強力な機能です。
正しく理解し、活用することで、データ分析のスキルが一段と向上するでしょう。
この記事が、インデックス(index)の基礎から応用までの理解に役立てば幸いです。


コメント